Cindy's Final Report
Final report
This semester I learned a lot in this course. Actually, I did not learn any about the computer vision, pattern precognition, or image processing before. I think the only things I already learned about this topic or the knowledge close to this lesson the is the filter and the gradient decent. In the class, teacher teach us step by step. It is not give us a lot of equation and how to calculate it and get the answer. The teacher tell us start from a concept, that what is pattern recognition, what is neural network and deep neural network, how is pattern precognition and neural network doing.
After I learn the such knowledge from the class and the reading homework, I have to read a chapter and make presentation to introduce what I read, learn, and know in the chapter I study. This is really a big challenge. It not only just study a book and say you know what is this book is talking about, you need to really know and can explain what the book is talking. I need to try to pick the main concept and find four to five important point out to make my presentation more numerous. This time presentation the different part between other presentation is not the english presentation, is your classmate will ask some question to you after your presentation. You can’t know what question they will ask you, but teacher is nice he put the question from the classmate online before the class, let presenter can think and find the answer.
Moreover, in the final homework, the presentation in english, the group discussion, or the programming content, they are the things I never try in the university in the course about the electrical engineering. It is a new experience and a good chance to practice my english on reading, listening, speaking, and writhing. In the group discussion, at the beginning, it is a little shy to speak english in front of the classmate, because I always feel my speaking is not really good especially on the professional topic, that is my weakly part. . In the programming content, I choose that using “MATLAB” to do this program. This is a little hard because if using Python, there is a code is ready to compute, but for MATLAB I need to find the code what teacher want.
Introduction
What is pattern recognition? It is easy for people to differentiate the sound, a photo, or a handwritten word, but it is really difficult for machine to solve this kind of problem. That computer can interact more effectively because of the pattern recognition. However, some problems in pattern recognition are not solved yet. The goal of pattern recognition is to build machine that can recognize the pattern.
What is neural network and deep neural network? The neural network, also called artificial neural network, is created from the natural model that the central nervous system of animal. It only has one hidden layer in the perceptron. The neural network is using bias and weight to update the neuron with time, and let the neurons make the accuracy much better. That just like our human always learning from the examples, the neural network also can do it. The deep neural network is come from the neural network, but it has more than one hidden layer between the input and output layers, and it is a kind of deep learning architectures. It can model complex non-linear relationships. And the deep neural network can be used in recognition that trained with the standard backpropagation algorithm.
Moreover, why neural network and deep neural network can be a good pattern recognition method? The neural network can learn from the example which is the input at the training step. Neural network is a good method of the pattern recognition, that it can learn depends on the input and correct the error at the output. So it can train with high accuracy.
My reading contents
Reading 1:What is pattern recognition
What is pattern recognition? Generally, it is easy for people to differentiate the sound or a handwritten word, but it is difficult for computer to solve the problem. At the last half century, because of pattern recognition that computer can interact more effectively with humans and the natural world. However, some problems in pattern recognition are not solved yet. The goal of pattern recognition is to build machine that can recognize pattern. Pattern recognition is used in a lot of applications such as DNA sequence identification, fingerprint identification, and optical character recognition. Actually, those identifications are really common in our life now.
There are two fundamental concepts for the pattern recognition system that statistical and structural. To discriminate among data from different groups that statistics means the data based on quantitative features, and structure means based on the morphological interrelationship present within the data. A typical pattern recognition system contains sensor, a preprocessing mechanism, a feature extraction mechanism, a classification or description algorithm, and a set of examples already classified or described.
There are five steps of pattern recognition. The first step is sensing that where the system input data from. The second step is segmentation and grouping, that is to separate the object in overlapping image. Third, feature extraction is to find the feature of the object. Forth, classification is to find and decide the group for our input. Finally, post processing is the output of the system.
This semester I learned a lot in this course. Actually, I did not learn any about the computer vision, pattern precognition, or image processing before. I think the only things I already learned about this topic or the knowledge close to this lesson the is the filter and the gradient decent. In the class, teacher teach us step by step. It is not give us a lot of equation and how to calculate it and get the answer. The teacher tell us start from a concept, that what is pattern recognition, what is neural network and deep neural network, how is pattern precognition and neural network doing.
After I learn the such knowledge from the class and the reading homework, I have to read a chapter and make presentation to introduce what I read, learn, and know in the chapter I study. This is really a big challenge. It not only just study a book and say you know what is this book is talking about, you need to really know and can explain what the book is talking. I need to try to pick the main concept and find four to five important point out to make my presentation more numerous. This time presentation the different part between other presentation is not the english presentation, is your classmate will ask some question to you after your presentation. You can’t know what question they will ask you, but teacher is nice he put the question from the classmate online before the class, let presenter can think and find the answer.
Moreover, in the final homework, the presentation in english, the group discussion, or the programming content, they are the things I never try in the university in the course about the electrical engineering. It is a new experience and a good chance to practice my english on reading, listening, speaking, and writhing. In the group discussion, at the beginning, it is a little shy to speak english in front of the classmate, because I always feel my speaking is not really good especially on the professional topic, that is my weakly part. . In the programming content, I choose that using “MATLAB” to do this program. This is a little hard because if using Python, there is a code is ready to compute, but for MATLAB I need to find the code what teacher want.
Introduction
What is pattern recognition? It is easy for people to differentiate the sound, a photo, or a handwritten word, but it is really difficult for machine to solve this kind of problem. That computer can interact more effectively because of the pattern recognition. However, some problems in pattern recognition are not solved yet. The goal of pattern recognition is to build machine that can recognize the pattern.
What is neural network and deep neural network? The neural network, also called artificial neural network, is created from the natural model that the central nervous system of animal. It only has one hidden layer in the perceptron. The neural network is using bias and weight to update the neuron with time, and let the neurons make the accuracy much better. That just like our human always learning from the examples, the neural network also can do it. The deep neural network is come from the neural network, but it has more than one hidden layer between the input and output layers, and it is a kind of deep learning architectures. It can model complex non-linear relationships. And the deep neural network can be used in recognition that trained with the standard backpropagation algorithm.
Moreover, why neural network and deep neural network can be a good pattern recognition method? The neural network can learn from the example which is the input at the training step. Neural network is a good method of the pattern recognition, that it can learn depends on the input and correct the error at the output. So it can train with high accuracy.
My reading contents
Reading 1:What is pattern recognition
What is pattern recognition? Generally, it is easy for people to differentiate the sound or a handwritten word, but it is difficult for computer to solve the problem. At the last half century, because of pattern recognition that computer can interact more effectively with humans and the natural world. However, some problems in pattern recognition are not solved yet. The goal of pattern recognition is to build machine that can recognize pattern. Pattern recognition is used in a lot of applications such as DNA sequence identification, fingerprint identification, and optical character recognition. Actually, those identifications are really common in our life now.
There are two fundamental concepts for the pattern recognition system that statistical and structural. To discriminate among data from different groups that statistics means the data based on quantitative features, and structure means based on the morphological interrelationship present within the data. A typical pattern recognition system contains sensor, a preprocessing mechanism, a feature extraction mechanism, a classification or description algorithm, and a set of examples already classified or described.
There are five steps of pattern recognition. The first step is sensing that where the system input data from. The second step is segmentation and grouping, that is to separate the object in overlapping image. Third, feature extraction is to find the feature of the object. Forth, classification is to find and decide the group for our input. Finally, post processing is the output of the system.
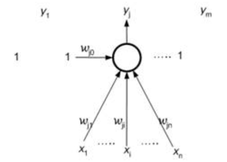
Figure 1The architecture of the Network of Perceptrons
Reading 2:Linear classifier and neural networks
The Network of perceptrons is the first successful model in neural network for the past years. The architecture of the network of perceptrons is as Figure 1. For the one layer network there is n input and m output. And the input all is the input for each output. Represented that the input x1…xn is the real states, the output y1…ym is the binary states. Moreover wij is a real synaptic weight and wj0=-hj is a bias that the output neurons compare to a formal unit input x0.
The classification in a single perceptron can splitting up the input data space to two classes. Between two classes there is a decision boundary line splitting a plane to two half-spaces. There is a function can describe the line, and can easy to decide the neuron is belong to which class. This input can classified by single perceptron called linearly separable patterns.
On the plane or 2-D prototype, it is more easy to use the vector to help us. We usually want to find the length of vector even for input vector (x=x1, x2, …xn )or weight vector(w=w1, w2, …wn). If we want to find the relation between two vector, we compute the inner product to find the relationship.
There is two basic methods to select a suitable weight vector. The first, “by off-line calculation of weight”. It is easy to compute the weight vector, if the relation is simple. The second, “by learning procedure”. There is a set of input-output vectors in order to training vector to find the best classification.
Reading 3: How does machine learning work: decision tree as an example
In the machine learning, how to find or identify the better separated boundary is really important. The good boundary can help the machine learning classified data with high accurate rate. There are some step can let us fellow. For a set of data, first, we can use our intuition to classify data, and than adding nuance is that adding another dimension deeply separate data. We can draw boundaries that depends on these dimensions and create the model with some dimensions also called training model. In different kind of pattern recognition has different training model.
For machine learning, we use decision tree that at one time look at one variable. In the decision tree, the fork classified the data into two branches based on a dimension value. The value between two branches called a split point. This value need to pick the best value that can use some function to calculate it. If the value do not choose the best, it may be false negatives or false positives. After the first split point, we add another split point with another dimension value, and like this process that we repeat the process again and again is called recursion. In training model, we are able to let the accuracy approach to 100%. If, in test model, we want to predict the test data, it will has some error. This is called overfitting. We can clear see in Figure.2. The training data according to the size of tree is increasing, the accuracy is also increasing. However, the test data start to decrease when the size of tree is bigger then 10.
The Network of perceptrons is the first successful model in neural network for the past years. The architecture of the network of perceptrons is as Figure 1. For the one layer network there is n input and m output. And the input all is the input for each output. Represented that the input x1…xn is the real states, the output y1…ym is the binary states. Moreover wij is a real synaptic weight and wj0=-hj is a bias that the output neurons compare to a formal unit input x0.
The classification in a single perceptron can splitting up the input data space to two classes. Between two classes there is a decision boundary line splitting a plane to two half-spaces. There is a function can describe the line, and can easy to decide the neuron is belong to which class. This input can classified by single perceptron called linearly separable patterns.
On the plane or 2-D prototype, it is more easy to use the vector to help us. We usually want to find the length of vector even for input vector (x=x1, x2, …xn )or weight vector(w=w1, w2, …wn). If we want to find the relation between two vector, we compute the inner product to find the relationship.
There is two basic methods to select a suitable weight vector. The first, “by off-line calculation of weight”. It is easy to compute the weight vector, if the relation is simple. The second, “by learning procedure”. There is a set of input-output vectors in order to training vector to find the best classification.
Reading 3: How does machine learning work: decision tree as an example
In the machine learning, how to find or identify the better separated boundary is really important. The good boundary can help the machine learning classified data with high accurate rate. There are some step can let us fellow. For a set of data, first, we can use our intuition to classify data, and than adding nuance is that adding another dimension deeply separate data. We can draw boundaries that depends on these dimensions and create the model with some dimensions also called training model. In different kind of pattern recognition has different training model.
For machine learning, we use decision tree that at one time look at one variable. In the decision tree, the fork classified the data into two branches based on a dimension value. The value between two branches called a split point. This value need to pick the best value that can use some function to calculate it. If the value do not choose the best, it may be false negatives or false positives. After the first split point, we add another split point with another dimension value, and like this process that we repeat the process again and again is called recursion. In training model, we are able to let the accuracy approach to 100%. If, in test model, we want to predict the test data, it will has some error. This is called overfitting. We can clear see in Figure.2. The training data according to the size of tree is increasing, the accuracy is also increasing. However, the test data start to decrease when the size of tree is bigger then 10.
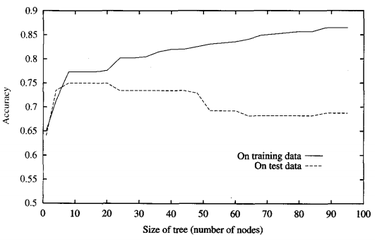
Figure.2 The overfitting in the decision tree
Moreover, Decision forest liked the decision tree is a classification, but the only one thing different is decision forest included some decision tree in it. We can grow n different decision tree in the same time, that it try to fix many problem. If we randomly split it up into different set, we also called it random forest.
Reading 4: Perceptron learning algorithm
The perceptron is a kind of linear classifier, also called artificial neural network. The simple perceptron has some input combined to one output (Figure 3). The input can be the outputs of other perceptrons or come from the environment. The input data always has a bias unit and the value is 1. The input xj, j = 1, . . . , d, is real, w0 is the bias unit, and y is output. We also can write the perceptron as a dot product, that the bias weight and input are included.
Reading 4: Perceptron learning algorithm
The perceptron is a kind of linear classifier, also called artificial neural network. The simple perceptron has some input combined to one output (Figure 3). The input can be the outputs of other perceptrons or come from the environment. The input data always has a bias unit and the value is 1. The input xj, j = 1, . . . , d, is real, w0 is the bias unit, and y is output. We also can write the perceptron as a dot product, that the bias weight and input are included.
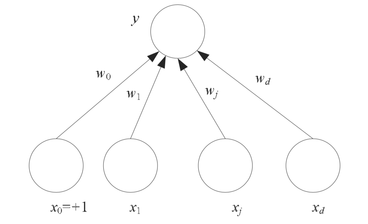
Figure 3. Perceptron
If the perceptron has more than 1 output (see Figure 4), we called parallel perceptron and for the output we will choose the maximum output or the output that more close to our need.
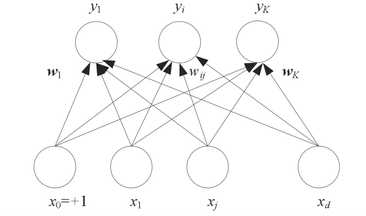
Figure 4. Parallel Perceptron
For the learning algorithm of perceptron, we need to know get the weight vector in the training example. There are two rule: the perceptron rule and the delta rule. According to the the perceptron rule, the weight vector is begin with random weights, and corrected the weights. The delta rule is the rule for those nonlinearly separable examples. It use the gradient descent to correct the weight vector.
Reading 5:MLP and XOR
A perceptron only has single layer and it can only solve the problem having linear function. Like the XOR, the nonlinear problem cannot be solved by single layer perceptron, so we need the multilayer perceptron, also called MLP, to help us solve the nonlinear problem. This multilayer perceptron has the hidden layer between the input layer and the output layer. We can see the structure in figure 1. xj, j = 0, . . . , d are the inputs unit and zh are the hidden units. x0 and z0 are the bias unit for each layer. yi is output unit. whj and vih are weights in there layer.
Reading 5:MLP and XOR
A perceptron only has single layer and it can only solve the problem having linear function. Like the XOR, the nonlinear problem cannot be solved by single layer perceptron, so we need the multilayer perceptron, also called MLP, to help us solve the nonlinear problem. This multilayer perceptron has the hidden layer between the input layer and the output layer. We can see the structure in figure 1. xj, j = 0, . . . , d are the inputs unit and zh are the hidden units. x0 and z0 are the bias unit for each layer. yi is output unit. whj and vih are weights in there layer.
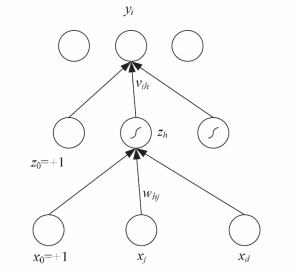
Figure 5. The structure of a multilayer perceptron
In the XOR case, if we want to classified in XOR case by using linear classification, it is impossible. We usually need at least two line to separated the data. However, if we use multilayer perceptron, it is easy to solve. For the ligic function (x1 XOR x2), we can using boolean logic to separate the function into (x1 AND ∼x2) OR (∼x1 AND x2).
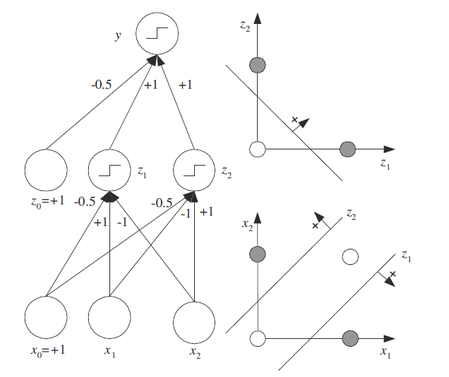
Figure 6.The multilayer perceptron that solves the XOR problem.
Now, we have two AND and one OR. At first layer, we set two parallel perceptron to decide the AND function, and the upper-layer perceptron that get the input from two parallel output, is decided the OR function. In the figure 2, x1 and x2 are the input for the first layer, and z1 and z2 are the output of the first layer. In the hyperplane, z1 and z2 are two decision line to separate the plane.
Reading 6: Backpropagation learning algorithm
This reading is foucs on the backpropagation algorithm. In the backpropagation algorithm, we will talk about the sigmoid function and the gradient descent.
Why use sigmoid for multilayer perceptron? Sigmoid neurons are really similar to perceptrons, but it has benefit is that it can has small change in weight and bias, and then let the output has small change. The weight value is not 0 or 1. It become 0 to 1, so weight can be modify. There is a function called sigmoid function (shown in Figure 7)
Reading 6: Backpropagation learning algorithm
This reading is foucs on the backpropagation algorithm. In the backpropagation algorithm, we will talk about the sigmoid function and the gradient descent.
Why use sigmoid for multilayer perceptron? Sigmoid neurons are really similar to perceptrons, but it has benefit is that it can has small change in weight and bias, and then let the output has small change. The weight value is not 0 or 1. It become 0 to 1, so weight can be modify. There is a function called sigmoid function (shown in Figure 7)
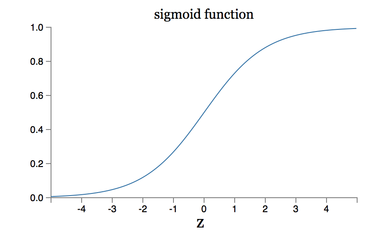
Figure 7. sigmoid function
What is backpropagation algorithm? Backpropagation, called “backward propagation of errors”, usually combined with the gradient descent and to train artificial neural networks. Backpropagation requires each input value has a known desired output and to calculate the loss function gradient. It is considered be a supervised learning.
Backpropagation learning algorithm can seen as two steps propagation and weight update.
Gradient descent is also called steepest descent. If the function F(x) is defined and differentiable at point a, then function F(x) at point a, fallowing negative gradient of F will decreases fastest.
My final presentation
My final presentation topic is about the backpropagation algorithm that is the main of learning in the neural network. The goal of backpropagation algorithm is to compute the partial derivatives of cost function. There is an algorithm called fast matrix-based algorithm that will using in the backpropagation algorithm. Before we talk about the backpropagation algorithm, let us talk about the fast matrix-based algorithm first. In the neural network, we have a function shown below equation 1. in the neuron network the weight we use the symbol wjkl, it include some information that the weight is that the kth neuron in the number (l − 1) layer to the jth neuron in the lth layer. And we transform to the matrix-based form, see the equation 2. In the matrix form is more easy for human and machine to calculate.
Backpropagation learning algorithm can seen as two steps propagation and weight update.
- propagation:
- Propagation has two step included forward propagation, having training pattern input in order to get the propagation's output activations, and backward propagation, what to find the delta between the actual output and targeted output values.
- Weight update
- To get the gradient of the weight from multiply the output delta and input activation. And then multiply a percentage to the gradient and add to the weight.
Gradient descent is also called steepest descent. If the function F(x) is defined and differentiable at point a, then function F(x) at point a, fallowing negative gradient of F will decreases fastest.
My final presentation
My final presentation topic is about the backpropagation algorithm that is the main of learning in the neural network. The goal of backpropagation algorithm is to compute the partial derivatives of cost function. There is an algorithm called fast matrix-based algorithm that will using in the backpropagation algorithm. Before we talk about the backpropagation algorithm, let us talk about the fast matrix-based algorithm first. In the neural network, we have a function shown below equation 1. in the neuron network the weight we use the symbol wjkl, it include some information that the weight is that the kth neuron in the number (l − 1) layer to the jth neuron in the lth layer. And we transform to the matrix-based form, see the equation 2. In the matrix form is more easy for human and machine to calculate.
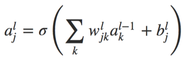
Equation 1.
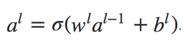
Equation 2.
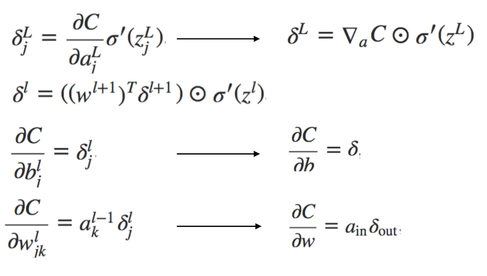
Figure 8. Four fundamental equation in backpropagation
My learning from group discussion
For the group discussion, I find that even you know the knowledge but maybe you can not describe and communicate to talk to other. When we are discussing, everyone are try to modify their sentence, so sometimes there is nobody talking. It is the part we need to learn. Actually, I stay quit is because I am not really know the answer of the question in not my presentation chapter. However, somebody maybe is try to transfer the sentence from Chinese to English so it wast some times.
My programming contents
In this homework, I am not as same as other classmate using Python to do the program, I use MATLAB to do it. There are some example in MATLAB toolbox, but it is really simple program. And in the MATLAB, the result usually like to use the figure to show. So, my program is not that plentiful as classmate. In my program, it only put one hidden layer between input and output layer.I find something that when we train it one time and train more time the performance is different. Training more times the performance is getting better and the line on the figure is more close to each other. We can see the different between the figure 9 (a) and (b). Even, the performance is getting better when the training time is increase, but it can not infinite increase.
For the group discussion, I find that even you know the knowledge but maybe you can not describe and communicate to talk to other. When we are discussing, everyone are try to modify their sentence, so sometimes there is nobody talking. It is the part we need to learn. Actually, I stay quit is because I am not really know the answer of the question in not my presentation chapter. However, somebody maybe is try to transfer the sentence from Chinese to English so it wast some times.
My programming contents
In this homework, I am not as same as other classmate using Python to do the program, I use MATLAB to do it. There are some example in MATLAB toolbox, but it is really simple program. And in the MATLAB, the result usually like to use the figure to show. So, my program is not that plentiful as classmate. In my program, it only put one hidden layer between input and output layer.I find something that when we train it one time and train more time the performance is different. Training more times the performance is getting better and the line on the figure is more close to each other. We can see the different between the figure 9 (a) and (b). Even, the performance is getting better when the training time is increase, but it can not infinite increase.
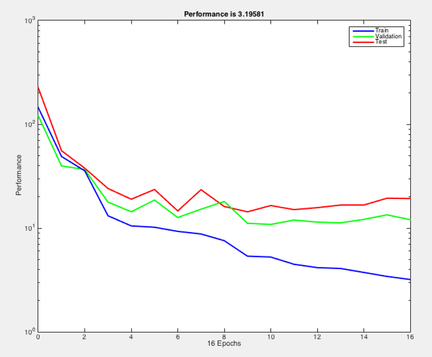
|
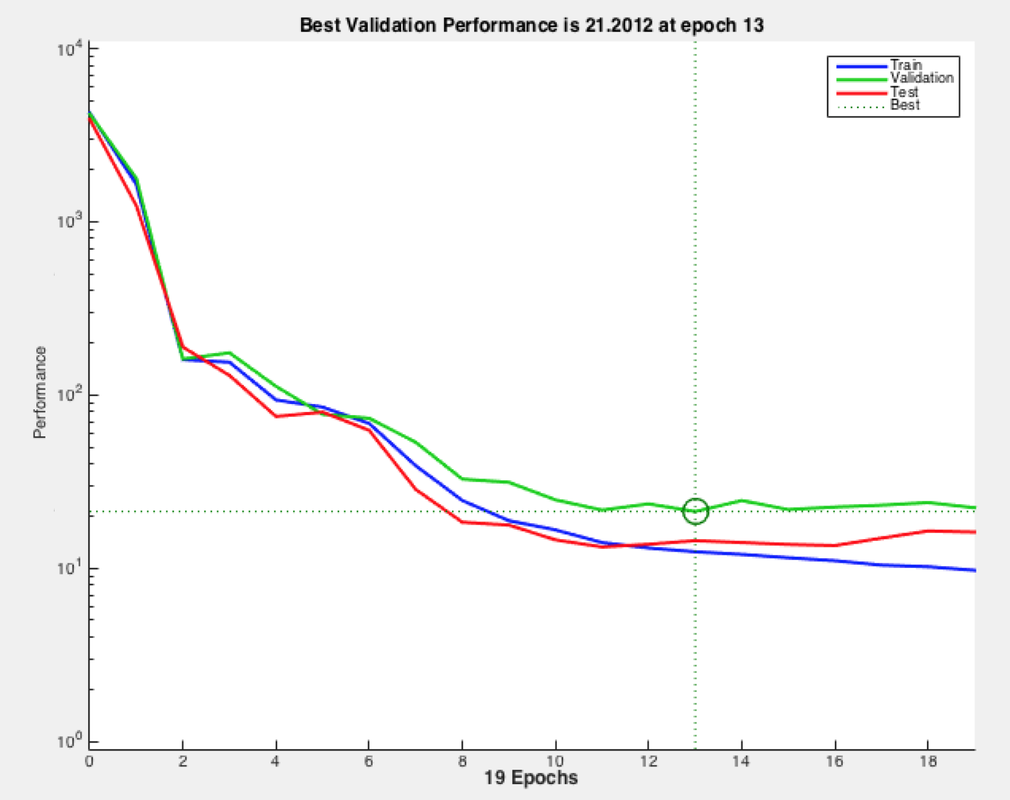
|
Figure 9. Program performance (a) training time =1 (b) training time =10
Conclusion
This semester in this course I really learn a lot, and I feel my english is getting better, too. Before, I am poor to write down the summary or find the main point in the article. After this semester training, I can do it. This course not only train my reading, also writing is improved. And the presentation let me not that nervous in front of the people. However, I am thinking me sentence even in writing or speaking need to use more beautiful word,is better.
