Daniel's Final Report
Introduction
For human, it is not difficult to recognize whether character, sound and image. But for computer, it is a very difficult problem because each pattern usually contains too much information leading to identification becomes a very complex task.
Pattern recognition is the science of making inferences from perceptual data, including the extraction and analysis of data feature and classification. Its application is very wide, including automated speech recognition, fingerprint identification, optical character recognition and much more. Thus, it is of central importance to artificial intelligence and computer vision.
But actually we have many problem in pattern recognition. When we want to find the feature or make a rule to recognize, we confuse easily because many special cases. It’s not ideal. neural network is great method that can approach the problem. Neural network can learn from many training example and it can automatically find the rules for pattern recognition.
Neural network’s Architecture
What is a neural network? It’s a model that simulate biological neural network and use to classify. A neuron in the neural network is also a simple classification. It’s shown in Figure 1.
For human, it is not difficult to recognize whether character, sound and image. But for computer, it is a very difficult problem because each pattern usually contains too much information leading to identification becomes a very complex task.
Pattern recognition is the science of making inferences from perceptual data, including the extraction and analysis of data feature and classification. Its application is very wide, including automated speech recognition, fingerprint identification, optical character recognition and much more. Thus, it is of central importance to artificial intelligence and computer vision.
But actually we have many problem in pattern recognition. When we want to find the feature or make a rule to recognize, we confuse easily because many special cases. It’s not ideal. neural network is great method that can approach the problem. Neural network can learn from many training example and it can automatically find the rules for pattern recognition.
Neural network’s Architecture
What is a neural network? It’s a model that simulate biological neural network and use to classify. A neuron in the neural network is also a simple classification. It’s shown in Figure 1.
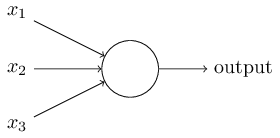
Figure. 1 neuron
A neuron can take several input and produce a binary output. These input can be input data or output of other neuron. Of course, the output also possibly be output or input of other neuron. Like our human, before we make a decision, we maybe think many factors and some factors may be important and some factors may be not. Neuron is same. These factors is our input and the weight is how important the factor is. Finally, Like we make a decision after we think, neuron get a binary output like yes or no after computing. This output is determined by activation function. The activation function input is weights sum and biases. The type of activation function is many. Like Rectified linear unit, step function and so more. Here we use the sigmoid function as our activation function. It’s shown in Figure 2.
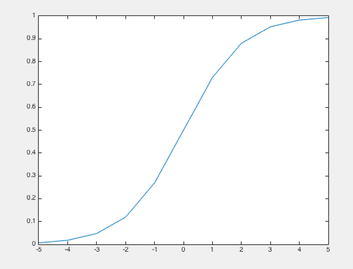
Figure. 2 sigmoid function
Obviously, only one neuron cannot make much complex decision. So we need a more complex network to solve more complex problem and the network consist of many neurons and each neuron is fully connected. It’s shown in Figure 3.
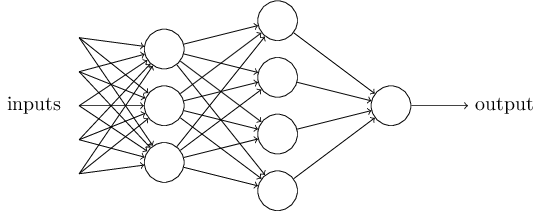
Figure. 3 multilayer network
Learning of neural network
Now we know how the neural network work but before network work, the network need to learn the right weights and biases. We use the stochastic gradient descent and back-propagation as our learning algorithm. The concept of learning is simple. First we initial our network. Then, we input the training data and get the output. Of course, we know expected output of training data. So we can compute the cost and according to this cost we modify weights and biases of the network. This is back-propagation. The way of modifying the weight is gradient descent. Originally we need to compute all of cost of training data and get its average as one step that is each weight updating each epoch. Although this method have higher accuracy but it’s too slow. So more often we use another gradient-base algorithm, that’s stochastic gradient descent. Stochastic gradient descent just compute a cost of one training example that is randomly select from training data as one step each epoch. Although its step is smaller but it’s faster each epoch. And that is difference with gradient descent. Or we also can randomly select a grouped data as a mini-batch and compute the cost of a mini-batch data as one step. This method can get a good accuracy and it isn’t too slow.
Learning speed is determined by how large step is. We use a parameter, called learning rate, to control the learning speed. If learning rate is too large, we possibly overshoot the global minimum of the cost. but if learning rate is too small, we possibly fall into the local minimum of the cost and cannot reach global minimum. So the choice of learning rate is also important.
Because step cannot too large. So in order to get right weights and biases, we have to train network many epochs. If train too few epochs, we cannot learn right weight and it’s called under-fitting. If train too much epochs, maybe we have a good accuracy in training data. But we have worse accuracy if input is not training data, like testing data or invalidation data. On the other hand, the model doesn’t have generality. This situation is called overfitting. Overfitting occurs when our model become more complex or cost function have too many parameter. So to avoid this problem, we may need to simply our network or modify the cost function. This solution is regularization techniques. One of mostly commonly techniques is dropout. When we train our network, we randomly delete half the hidden neurons in the network each epoch and repeat this process over and over. This is a powerful method to reduce overfitting.
Deep neural network
Although a shallow network is a powerful method to solve simple problem. But we have to know a fact. The deep network is more powerful than shallow network. Particularly we want to solve complex problem in patten recognition problem. The deep network always have higher accuracy than shallow network. But in fact, we are hard to train the deep neural network. If we cannot get right weights and biases, we know we cannot get good accuracy. Why are we hard to train the deep neural network? Because, in fact, the neuron’s learning speed in the different hidden layer is different. Neurons in the earlier hidden layer always learn more slowly than neurons in the later hidden layer and if our network change deeper and deeper, neurons in the earlier hidden layer will learn very very slow. We will hard to modify the weights and biases in the earlier hidden layer and more important problem is if our network learn too slow the network is likely to fall into local minimum of cost. It’s not ideal. This problem is the vanish gradient problem. But what cause it? The learning speed is determined by gradient. So the vanishing gradient problem is the gradient in the earlier hidden layer is too small. The gradient is determined by the derivative of activation function by chain rule. So we find the reason of this problem. Until now we use the sigmoid function as activation function. Because the derivative of sigmoid function is very small. So by chain rule, the gradient of neuron in earlier hidden layer must be very small and always smaller than neuron in later layer. So we can solve this problem by changing activation function, like Rectified linear unit(ReLU), or initialing the network by pre-training.
We know the deep neural network is more powerful than the shallow network. But until now we just use fully connected network. But if we want to solve more complex problem in the pattern recognition, like image recognition. That is not a good method because this network does not take into account the spatial structure of the images. So we have to use another network. That is convolutional neural network and it’s shown in Figure 4. Convolutional networks can help us train deep, many-layer networks, which are very good at classifying images.
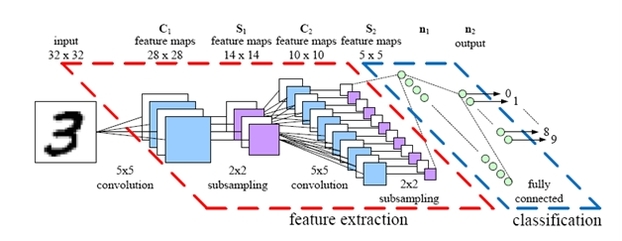
Figure. 4 convolution neural network
Programming implement
My program is in order to proof the vanishing gradient problem exist. I will try to train 4 kinds of network to solve the MNIST digit classification problem. These 4 kinds of network have different numbers of hidden layers.
The MNIST data set is my training data. Figure 5 is a few images from MNIST. The MNIST data set contains tens of the thousands of scanned images of handwritten digits, together with their correct classifications. It comes in two parts. The first part contains 60000 images to be used as training data. The second part is 10000 images to be used as test data. Each image is greyscale and 28 by 28 pixels in size.
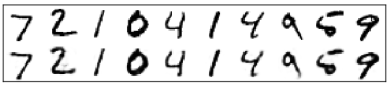
Figure. 5 the MNIST data
In our network, the input layer has 784 neurons, corresponding to the 784 pixels of input image. each hidden layer has 30 neurons and the output layer has 10 neurons corresponding to digit zero to nine.
first,we load the training data, test data and validation data. of course, the data set is MNIST handwritten digit data set.

Figure. 7 load training data
Then, we set up our network and train it. we train the network for 30 epochs, mini-batch is 10, learning rate is 0.1 and regularization lambda is 5. after each epoch we let the network classify the validation data and monitor its accuracy.

Figure. 8 set up 4 kinds of network and train
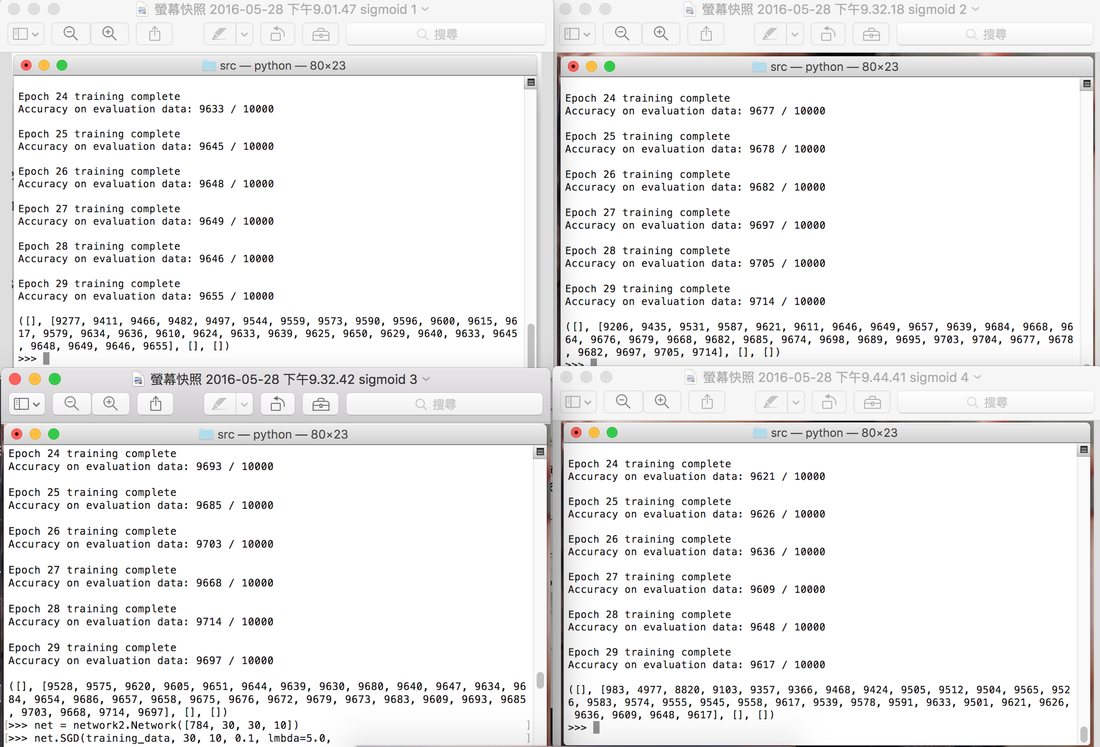
Figure. 9 monitor the result
We can see the training result in Figure. 9 and Table. 1. We can see clearly the deep network have higher accuracy but if our network become more deep, the accuracy is lower. So we have a problem and this problem is the vanishing gradient problem.

Table. 1 training result
Conclusion
In the recent year, neural network is very hot topic in the pattern recognition and computer vision. Deep neural network even can solve many complex problem in the real world, like speech, image and more and more. Neural network is also like magic. we just need to give the data and the network can learn everything. Even if we don’t know the weight and bias mean. Can neural networks and deep learning lead to artificial intelligence? What about general-purpose thinking computers? These problem is ongoing researches and I believe in not far future many fantasy will be come true.
