Jacky's Final Report
Introduction
What is pattern recognition:
Pattern recognition is a machine learning that we can use the pattern of the objects or shapes to recognize the data we want. It’s a very challenging task. We human beings have brains with complex structure and we are logically, let’s take an example, a picture with dogs and cats in it, we can simply point out which one is dog, and which one is cat, but for computers, when a picture is input into the computer as a data, computers only receive a bunch of numbers, so how does the computer recognize dogs and cats in that picture? Computers can gather information like height, width, color, shapes… and so on, but does everyone look the same? No, the way to recognize is to make sense, have logic, something like if the computer has a input that isn’t skin color, it can tell that it’s not a human being, because we don’t have blue or green skin color. The way to gather everything up is to use neural network and deep neural network.
The goal of the pattern recognition is to “perfectly” recognize the pattern, but this only work on the things with clearly pattern, we still need to deal with the patterns that are not easy to recognize, since we are discussing about visual recognition in the course, so I’m not going to talk about speech recognition.
Pattern recognition will make our lives more convenient, and there are already some product that use pattern recognition, such as self-driving cars, robots, and also there are places that use this technique, like electronic toll collection(ETC) in the highway, e-Gate in airport for fast pass, and so on.
What is neural network / deep neural network:
An artificial neural network is a network that simulates biological nervous system, such as human beings’ brain. The idea is that the network is consist of a large number of neurons, and those neurons can help us solve complex problems, because we human beings can learn by example, also artificial neural network is able to learn by example. The way it works is to make a lot of questions for a problem, through those questions, neural network will get a answer that makes sense for the problem.
Why neural network / deep neural network can be a good pattern-recognition method:
From the section above, I already mention that artificial neural network can learn by examples. Neural network is a good method for pattern recognition is because that it can learn depends on the data you input and it will create its own rules or limitations in the net, and this property can make the accuracy better. When you get a good model of neural network that was trained with hight accuracy, you can always use this model to do recognizing.
Reading
Chapter 1 Using neural nets to recognize handwritten digits:
I’m going to explain things in neural network first, then explain how it works to train and recognize. First of all, we need to know about artificial neurons, I’ll start with perceptron, it has several inputs and has one output(Figure 1), and we can simply use the equation to calculate the output(Equation 1) using weight and bias.
Chapter 1 Using neural nets to recognize handwritten digits:
I’m going to explain things in neural network first, then explain how it works to train and recognize. First of all, we need to know about artificial neurons, I’ll start with perceptron, it has several inputs and has one output(Figure 1), and we can simply use the equation to calculate the output(Equation 1) using weight and bias.
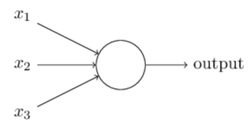
Figure 1 Perceptron
|
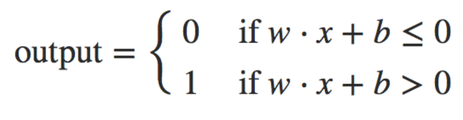
Equation 1 Perceptron
|
when you get more layers it’ll be more complex since there are more decisions to make, and we’ll call it multiple layer perceptron (MLP). Though there is perceptron in it, it doesn’t use perceptron, it use sigmoid neurons.
I think perceptron is a simple thing to start with neural network, but using sigmoid neurons will be better. Sigmoid neurons also take several inputs and have a output, the difference it that perceptron takes only 0s and 1s, but sigmoid neuron takes value between 0 ~ 1, and also have output between 0 ~ 1, and sigmoid neurons use sigmoid function(Equation 2), and the shape of sigmoid function is shown below(Figure 2).
I think perceptron is a simple thing to start with neural network, but using sigmoid neurons will be better. Sigmoid neurons also take several inputs and have a output, the difference it that perceptron takes only 0s and 1s, but sigmoid neuron takes value between 0 ~ 1, and also have output between 0 ~ 1, and sigmoid neurons use sigmoid function(Equation 2), and the shape of sigmoid function is shown below(Figure 2).
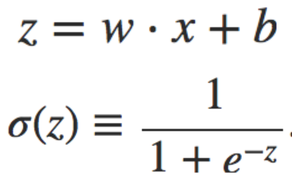
Equation 2 Sigmoid function
|
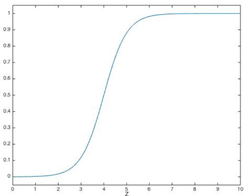
Figure 2 Shape of sigmoid function
|
Using the shape of sigmoid function, the smoothness 𝝈 means the small changes in weight and bias, it’s easier to figure out how it’ll influence the output(Equation 3), and this property makes learning possible.
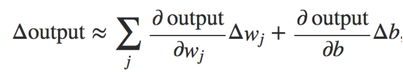
Equation 3 Changes for the output
After introducing artificial neurons, let’s talk about architecture, it’ll be including input layer, hidden layers, and output layer(Figure 3). And there will be two kinds of neural network, first is feedforward neural network and the second is recurrent neural network. Feedforward neural network is more widely used, and this mean the the output from one layer is the input for the next layer. Then, for recurrent neural network, it’s actually the opposite of feedforward, the output from one layer is the input of previous layer, and there’ll be a limited duration of time to avoid the output change immediately.
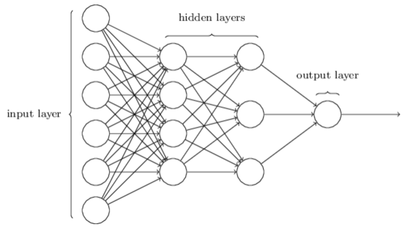
Figure 3 Architetture of MLP
|
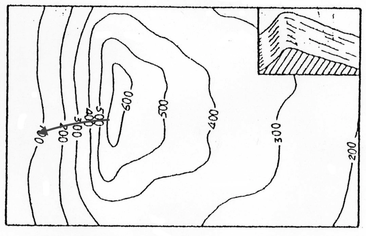
Figure 4 Gradient Descent
|
Here we are going to talk about the learning algorithm, gradient descent, it is a way to find the set of weights and bias that make the cost as small as possible, it’s an idea from finding the fastest direction is go down the valley(Figure 4), gradient descent will learn by training every data and find the gradient, then update weights and bias. The cost function in chapter 1 used is quadratic cost function(Equation 5), also called mean squared error(MSE), we need to minimize the cost as small as possible, and this can be done by gradient descent. I’ll use v1 and v2 as weight and bias for example, let’s take a look at the following equations(Equation 6), the change in the cost will be the partial derivatives times the vector change, and we get ΔC, then let Δv be the vector change for v1 and v2, we can get a gradient vector by the differential with v1 and v2 using cost, then we can get ΔC is gradient vector multiply vector change. For the last two formula, we need make ΔC negative, where eta is learning rate, it’s a small positive parameter. Since Δv will always be negative if gradient C and eta are positive, the cost will become smaller and smaller.
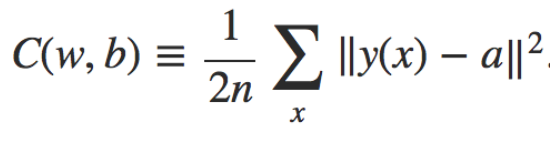
Equation 5 Quadratic cost function
|
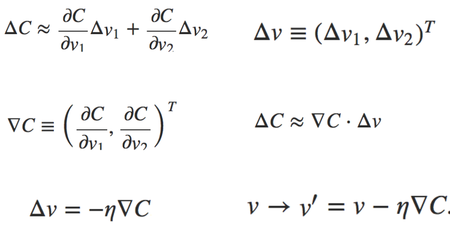
Equation 6 Gradient descent
|
but training with every training data takes time, so we can use stochastic gradient descent, it’ll randomly pick a groups of data(which call mini-batch), and then update after training every each batch, this make learning faster, but it won’t be perfect, and we don’t have to, because the point we are focusing is to find the weight and bias, stochastic gradient descent is commonly used and powerful in learning.
After explaining neurons and algorithm, I will go onto handwritten digits classifying. There are going to be two sub-problems for recognizing digits. First is to separate digits into a sequence of separate digits, second classify the individual digits, this mean we’ll need segmentation and individual digit classifier, since we are discussing about neural network, I’m not going to talk about segmentation.
Here we are going to use MNIST data set(Figure 5), which is commonly used in machine learning. It is divided into two part, first part is training data set including 60,000 images and second is test data set including 10,000 images. The training data set are examples from 250 writers, composed of 30,000 patterns from SD-3 and 30,000 patterns in SD-1. The test data set is composed of 5,000 patterns from SD-3 and 5,000 patterns in SD-1.
After explaining neurons and algorithm, I will go onto handwritten digits classifying. There are going to be two sub-problems for recognizing digits. First is to separate digits into a sequence of separate digits, second classify the individual digits, this mean we’ll need segmentation and individual digit classifier, since we are discussing about neural network, I’m not going to talk about segmentation.
Here we are going to use MNIST data set(Figure 5), which is commonly used in machine learning. It is divided into two part, first part is training data set including 60,000 images and second is test data set including 10,000 images. The training data set are examples from 250 writers, composed of 30,000 patterns from SD-3 and 30,000 patterns in SD-1. The test data set is composed of 5,000 patterns from SD-3 and 5,000 patterns in SD-1.

Figure 5 Example of MNIST data set
Now we will go onto multiple layer perceptron for recognizing. A example is using a three-layer neural network(Figure 6) to solve individual digit, input layer with 784 neurons, hidden layer with 15 neurons, and 10 neurons for output layer. The MNIST training data is 28 by 28 pixel, so that’s why we need 28x28=784 neurons for input layer, and there are 10 digits for zero to nine, so we need 10 neurons for output layer, the number of neurons or layers in hidden layer decide how complex the net will be.
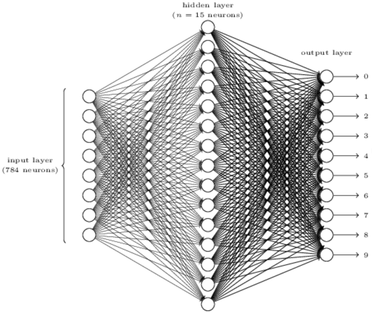
Figure 6 A simple network to recognize handwritten digits
Chapter 2 How the backpropagation algorithm works:
This chapter introduce about how backpropagation algorithm works and its math formulas. But the most important thing is to learn how it works and not to understand every math functions in it, it is also mention that we can skip this chapter.
Backpropagation algorithm is used to train multi-layer neural networks, what backpropagation do is to input training data and get outputs, then calculate the error vector and propagate to the previous layer, using cost function to compute gradient, and finally update the weights.
Chapter 3 Improving the way neural networks learn:
Chapter 3 introduce about cross-entropy, overfitting, and regularization. Cross-entropy is a way to avoid learning slow down, it’s use log function rather than using derivatives. In quadratic cost function mentioned in chapter 1, it’s use partial derivatives to calculate for the cost change, but in sigmoid function(Figure 2), the part where it’s near to 0 and 1, the slope will be very small, approaching zero, if we use derivatives that quadratic cost function used, it’ll learn slowly.
Then let’s go onto the overfitting, overfitting means that the net is over-trained, so the after accuracy of test data reach its peak it’ll start to decrease and make it worse, because the hypothesis is too close to the training data, this will happen if your training data is not enough or too much epochs to learn. The simplest way to avoid overfilling to opposite to the reason that cause overfitting, rather adding more training data or decrease epochs will be okay.
Another way to avoid overfitting is regularization, the idea of regularization is to limit the square of the weight, it will be limiting the weight to avoid the weight becomes too large for the hypothesis that is close to the training data, this can avoid over-training.
Chapter 4 A visual proof that neural nets can compute any function:
In this chapter, the most important thing is that using multiple layer perceptrons can solve any function, there are many examples with different layers, different neurons, different value of weights and biases, and the output will be different. The idea is to use more layers and more neurons with different value of weights and biases to make the net become more complex that are able to solve function you want. Let’s just take a example of XOR, using a perceptron can’t solve XOR because it’s a non-linear function, but using three layers (input layer, hidden layer, and output layer) we can solve XOR(Figure 7).
This chapter introduce about how backpropagation algorithm works and its math formulas. But the most important thing is to learn how it works and not to understand every math functions in it, it is also mention that we can skip this chapter.
Backpropagation algorithm is used to train multi-layer neural networks, what backpropagation do is to input training data and get outputs, then calculate the error vector and propagate to the previous layer, using cost function to compute gradient, and finally update the weights.
Chapter 3 Improving the way neural networks learn:
Chapter 3 introduce about cross-entropy, overfitting, and regularization. Cross-entropy is a way to avoid learning slow down, it’s use log function rather than using derivatives. In quadratic cost function mentioned in chapter 1, it’s use partial derivatives to calculate for the cost change, but in sigmoid function(Figure 2), the part where it’s near to 0 and 1, the slope will be very small, approaching zero, if we use derivatives that quadratic cost function used, it’ll learn slowly.
Then let’s go onto the overfitting, overfitting means that the net is over-trained, so the after accuracy of test data reach its peak it’ll start to decrease and make it worse, because the hypothesis is too close to the training data, this will happen if your training data is not enough or too much epochs to learn. The simplest way to avoid overfilling to opposite to the reason that cause overfitting, rather adding more training data or decrease epochs will be okay.
Another way to avoid overfitting is regularization, the idea of regularization is to limit the square of the weight, it will be limiting the weight to avoid the weight becomes too large for the hypothesis that is close to the training data, this can avoid over-training.
Chapter 4 A visual proof that neural nets can compute any function:
In this chapter, the most important thing is that using multiple layer perceptrons can solve any function, there are many examples with different layers, different neurons, different value of weights and biases, and the output will be different. The idea is to use more layers and more neurons with different value of weights and biases to make the net become more complex that are able to solve function you want. Let’s just take a example of XOR, using a perceptron can’t solve XOR because it’s a non-linear function, but using three layers (input layer, hidden layer, and output layer) we can solve XOR(Figure 7).
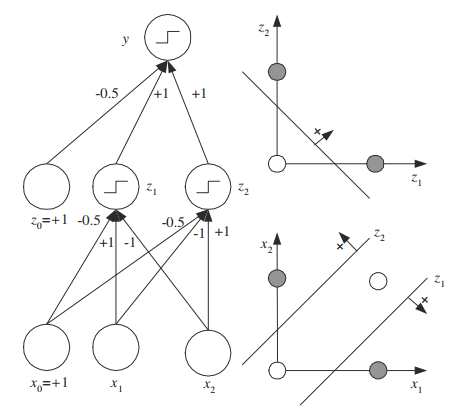
Figure 7 XOR problem
Chapter 5 Why are deep neural networks hard to train:
The most important thing in this chapter is vanishing gradient problem, this problem makes neural networks hard to train, and it’s a problem with nets that is based on gradient method, backpropagation algorithm we discuss in chapter 2 is a gradient based method, too. There will be two reasons for vanishing gradient descent, one is training with too many layers in the whole architecture, and the other one is caused by the activation function, such as sigmoid function or hyperbolic tangent. Since gradient methods is to learn small change in the weights and biases to affect the output, if the parameter(derivatives of weights or biases) on affect the output a little, it can’t learn effectively, or we can even say it’s not learning.
The ways to solve this problem is opposite to the reasons, if you get too many layers, just decrease the layers, if your activation function is not good for the nets, try another activation function would help. In chapter 5, there are examples with different numbers of layer, using one layer they get 96.48%, and get 96.90% for two layers, 96.57% for three layers, 96.53% for four layers, this is a vanishing gradient problem with too many layers, also there is an example of activation function, using sigmoid function that make the cost larger.
Chapter 6 Deep learning:
In this chapter, we’re focusing on the convolution neural network, and the basic ideas are local receptive fields, shared weights, and pooling. Let’s talk about local receptive fields and take a look at Figure 8 and Figure 9, you will see that different range of input data are input to different hidden layer, it only cares about the pixel that are close.
The most important thing in this chapter is vanishing gradient problem, this problem makes neural networks hard to train, and it’s a problem with nets that is based on gradient method, backpropagation algorithm we discuss in chapter 2 is a gradient based method, too. There will be two reasons for vanishing gradient descent, one is training with too many layers in the whole architecture, and the other one is caused by the activation function, such as sigmoid function or hyperbolic tangent. Since gradient methods is to learn small change in the weights and biases to affect the output, if the parameter(derivatives of weights or biases) on affect the output a little, it can’t learn effectively, or we can even say it’s not learning.
The ways to solve this problem is opposite to the reasons, if you get too many layers, just decrease the layers, if your activation function is not good for the nets, try another activation function would help. In chapter 5, there are examples with different numbers of layer, using one layer they get 96.48%, and get 96.90% for two layers, 96.57% for three layers, 96.53% for four layers, this is a vanishing gradient problem with too many layers, also there is an example of activation function, using sigmoid function that make the cost larger.
Chapter 6 Deep learning:
In this chapter, we’re focusing on the convolution neural network, and the basic ideas are local receptive fields, shared weights, and pooling. Let’s talk about local receptive fields and take a look at Figure 8 and Figure 9, you will see that different range of input data are input to different hidden layer, it only cares about the pixel that are close.
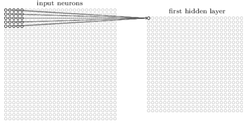
Figure 8 Local receptive field(1)
|
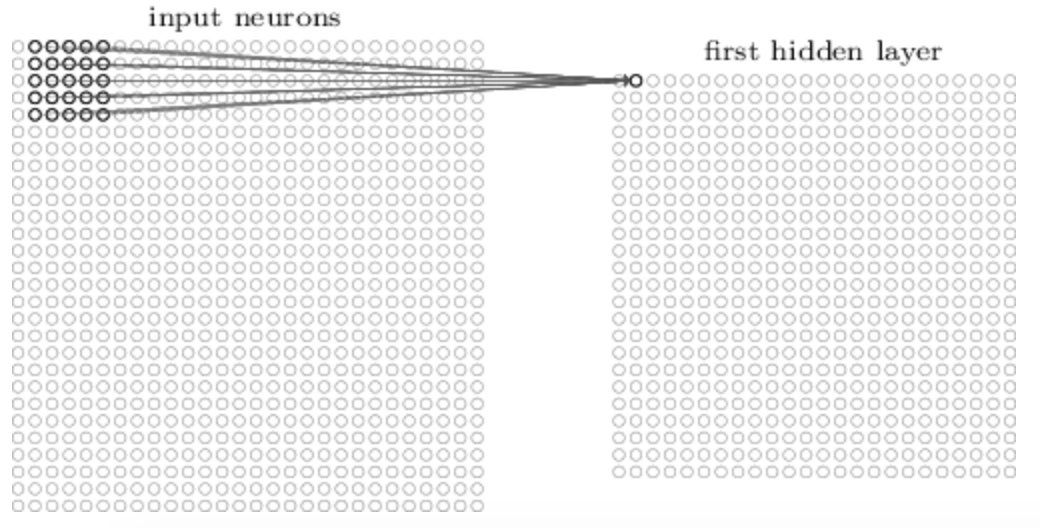
Figure 9 Local receptive field(2)
|
Then let’s talk about shared weight, it’s advantage is that it can decrease the parameter that are involved in convolution neural network. Finally, I will go onto pooling, pooling layer will alway be connected to the convolution layer, and it can simplify the output from convolution neural network. Combing everything together, we can get an architecture as Figure 10,the first layer is input layer, second is convolution layer, third is pooling layer, and the final is fully-connected layer.
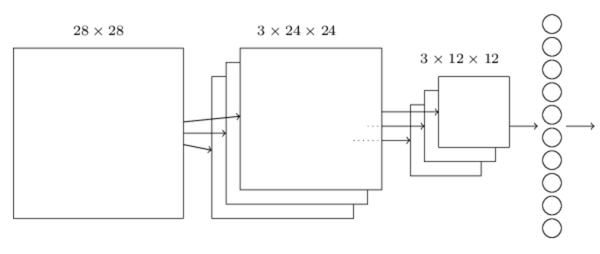
Figure 10 Deep neural network
Learning from group discussion
In group discussion, actually I learned more about using English in conversation. Things I learned for neural network is to clarify some concept, because I misunderstood some concepts for stochastic gradient descent, dropout, and overfitting.
For question 1:
I misunderstood about mini-batch in stochastic gradient descent. Stochastic gradient descent only randomly choose some data, and stochastic gradient descent with mini-batch is to separate data into different batch, the thing I mistaken is that I thought that stochastic gradient descent with mini-batch is to randomly choose some data, then randomly separate into batches from the chosen data.
For question 2:
We know about how it works, but we don’t really get all the mathematical formula, and it’s hard to explain and describe it.
For question 3:
Though I know that dropout is to ignore some neurons, but I don’t know how it really works to update, so I understand how it works after this discussion.
In group discussion, actually I learned more about using English in conversation. Things I learned for neural network is to clarify some concept, because I misunderstood some concepts for stochastic gradient descent, dropout, and overfitting.
For question 1:
I misunderstood about mini-batch in stochastic gradient descent. Stochastic gradient descent only randomly choose some data, and stochastic gradient descent with mini-batch is to separate data into different batch, the thing I mistaken is that I thought that stochastic gradient descent with mini-batch is to randomly choose some data, then randomly separate into batches from the chosen data.
For question 2:
We know about how it works, but we don’t really get all the mathematical formula, and it’s hard to explain and describe it.
For question 3:
Though I know that dropout is to ignore some neurons, but I don’t know how it really works to update, so I understand how it works after this discussion.
Programming
The programming I done in this course is about chapter 1 using neural nets to recognize handwritten digits. It’s using sigmoid neurons and stochastic gradient descent I’ve introduced in reading content, so I’m just going to explain the result I’ve got.
The code that is provided by this online book is to initial the weights and biases randomly. Then I start to train with different parameter. I’ll start with changing the neurons in hidden layer, and I got the best accuracy of 96.27% with 60 neurons, shown in Chart 1. Then change the epochs, and got the best accuracy of 95.51% with 30 epoch, shown in Chart 2.
The programming I done in this course is about chapter 1 using neural nets to recognize handwritten digits. It’s using sigmoid neurons and stochastic gradient descent I’ve introduced in reading content, so I’m just going to explain the result I’ve got.
The code that is provided by this online book is to initial the weights and biases randomly. Then I start to train with different parameter. I’ll start with changing the neurons in hidden layer, and I got the best accuracy of 96.27% with 60 neurons, shown in Chart 1. Then change the epochs, and got the best accuracy of 95.51% with 30 epoch, shown in Chart 2.
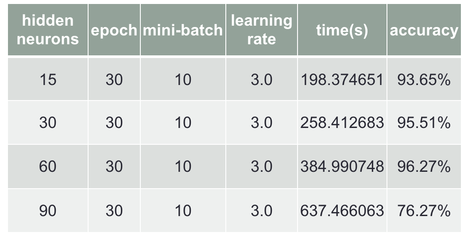
Chart 1 Changing in neurons
|
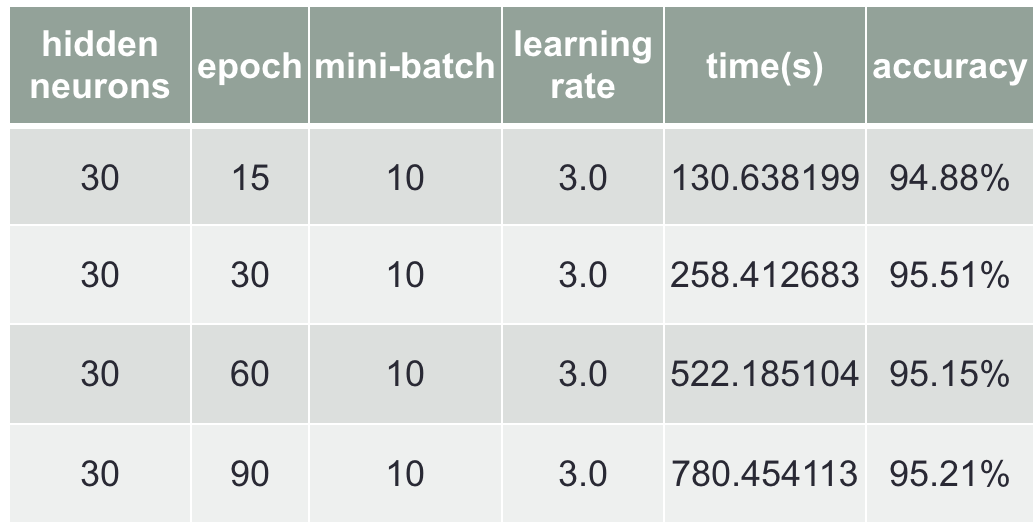
Chart 2 Changing in epoch
|
Third is to change mini-batch, and I got 95.51% with mini-batch of 10, shown in Chart 3. Finally change the learning rate, I got 95.51% with learning rate of 3.0, shown in Chart 4.
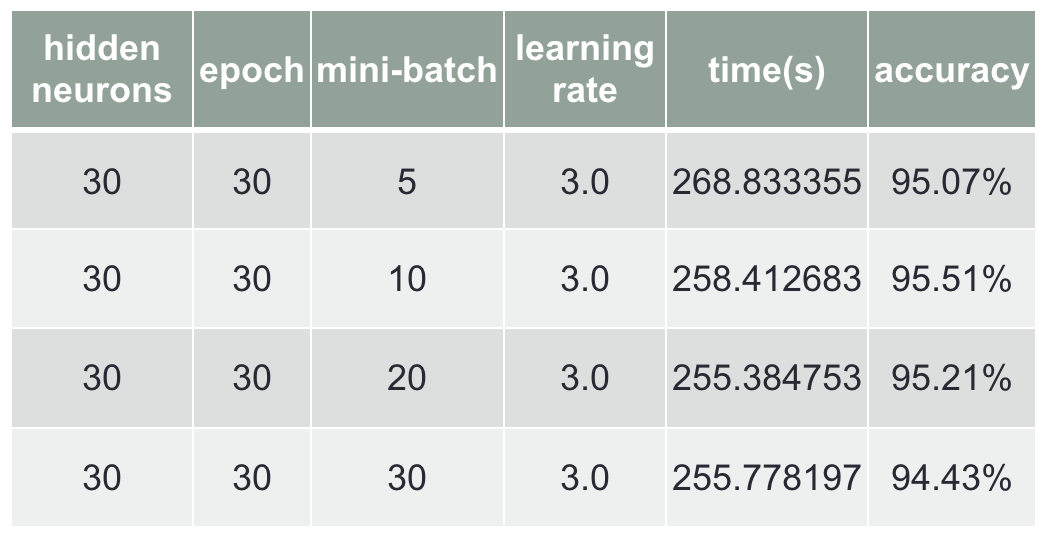
Chart 3 Changing in mini-batch
|
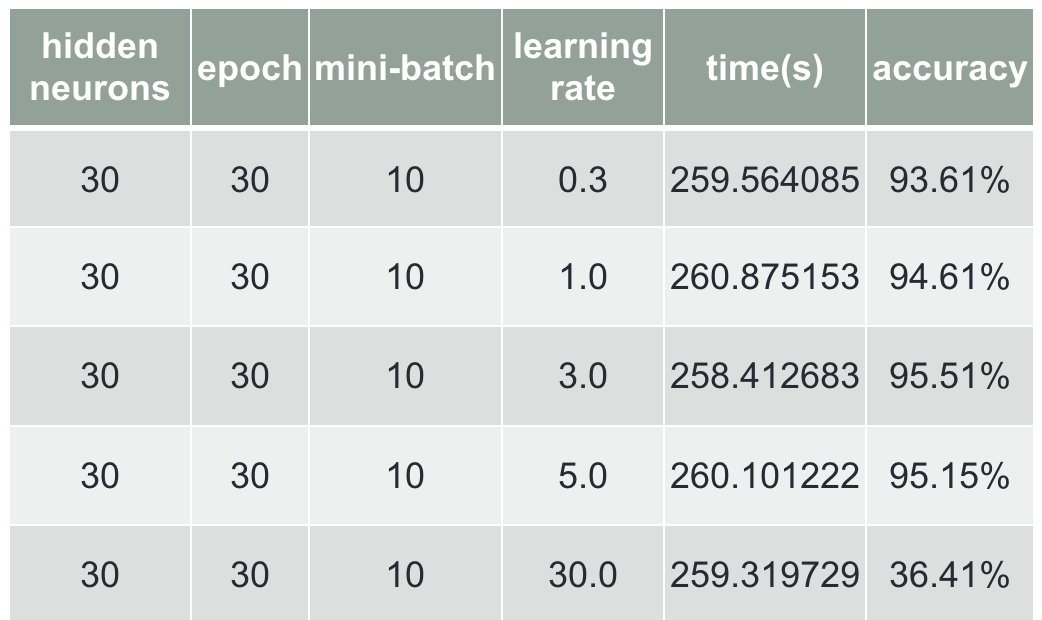
Chart 4 Changing in learning rate
|
After testing 4 parameters by fixing the other parameter, the best I got is 96.27% by changing neurons in hidden layer, so I’ll start from changing neurons in hidden layer to find the best parameter, shown in Chart 5.
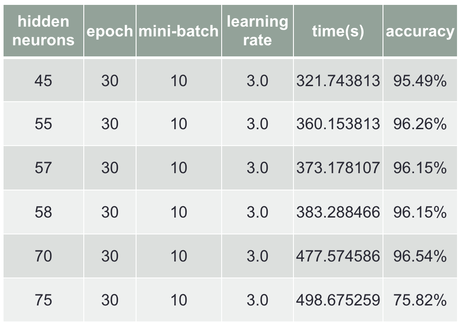
Chart 5 Finding best parameter value(1)
and I got 75.82% using 75 neurons in hidden layer, the reason that 70 neurons can get high accuracy is the weights and biases are initial well, so I keep testing by decreasing the neurons and use the parameter value I got from the test Chart 2~4, finally I got 96.40% for the best accuracy, shown in Chart 6.
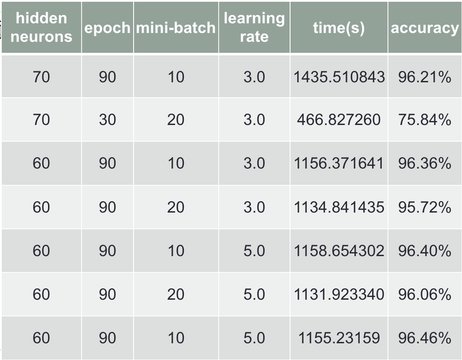
Chart 6 Finding best parameter value(2)
I also tried using two and three hidden layers, and I got 96.92% for using two hidden layers(Chart 7), and got 96.39% for using three hidden layers(Chart 8).
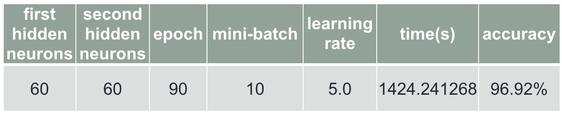
Chart 7 Using two hidden layers

Chart 8 Using three hidden layers
Conclusion
In this course, I learned about many things in neural network, and because this course is taught using English, and there are also oral presentation, English reading homework, and group discussion, so I also improve my English as well.
Neural networks will be popular in the future, not only on image recognition, but also on speech recognition, too. And also the google translation will be better for the future using neural nets, but not for now, many things that can use pattern recognition will be trends for the future, and I’m looking forward to it.
