Steffi's Final Report
Introduction:
The purpose of choosing this course to have a basic understanding about neural networks. While reading some research papers there were so many questions running in my mind like what does this mean, how does it work and was not able to sort out what was the author trying to explain in the journals. I thought I would get an answer for all of these questions and so I decided to choose this course.
Pattern Recognition is a branch of machine learning that focuses on the recognition of patterns and regularities in data. Humans are capable of identifying or recognizing but machines cannot. So it is necessary to train a machine to recognize, but how? PR systems are trained from labeled training data and is also known as supervised learning. When the labeled data is not available we go for unsupervised learning. There are “N” number of algorithms and they are chosen depending on a number of factors including the type of label output, learning, statistical and non-statistical, etc. Deep learning or deep machine learning methods falls under clustering algorithms. Various deep learning architectures like deep neural networks, convolutional neural networks, deep belief networks and recurrent neural networks. They are used in many fields like computer vision, speech recognition, and language processing.
Pattern recognition system:
The pattern recognition system includes a sequence of steps:
Sensing ---> Preprocessing---> Segmentation---> Feature extraction---> Classification---> Post-processing
Sensing unit is a hardware, input to the unit is from the real world. It uses a transducer to acquire signals. This signal is input to the next stage called preprocessing. Preprocessing uses many filtering and non-filtering methods that helps in noise reduction and object enhancement. The preprocessed image is given as input to segmentation stage. Image segmentation is the third step, it segments single object from the set of objects like boundary, edges. The output of the image segmentation is given as input to the fourth stage called feature extraction. It uses features like boundary, line segments, and shape to describe and represent segmented objects. The Classification stage uses the feature vector as input and assigns object to a recognized class. To help a computer to find the best classifier, training algorithm and training data is used. The training algorithm uses training data to find the best classifier. There are a number of classifiers and each classifier has an error rate. The best classifier has the lowest error rate of all the other classifiers.
Deep Neural Networks:
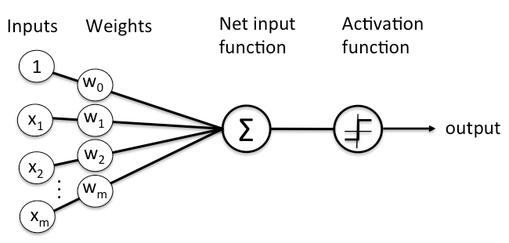
In DNN is an algorithm to recognize patterns. It consists of several layers with nodes, where the computation usually takes place. Figure 1 shows how the network works, the input and weights are summed and is passed through activation function and finally stage is output. The activation function may be either a perceptron or sigmoid. To learn or train a network, a training data set is needed. The output from the network is approximated for all training inputs which is defined by a cost function. This cost function is also known as Mean Square Error (MSE). The training algorithm called stochastic gradient descent aims to keep the cost function as small as possible. The cost function helps to figure out the performance of the network. High cost function results in poor performance of the network so it is necessary to keep the cost function as small as possible.
The purpose of choosing this course to have a basic understanding about neural networks. While reading some research papers there were so many questions running in my mind like what does this mean, how does it work and was not able to sort out what was the author trying to explain in the journals. I thought I would get an answer for all of these questions and so I decided to choose this course.
Pattern Recognition is a branch of machine learning that focuses on the recognition of patterns and regularities in data. Humans are capable of identifying or recognizing but machines cannot. So it is necessary to train a machine to recognize, but how? PR systems are trained from labeled training data and is also known as supervised learning. When the labeled data is not available we go for unsupervised learning. There are “N” number of algorithms and they are chosen depending on a number of factors including the type of label output, learning, statistical and non-statistical, etc. Deep learning or deep machine learning methods falls under clustering algorithms. Various deep learning architectures like deep neural networks, convolutional neural networks, deep belief networks and recurrent neural networks. They are used in many fields like computer vision, speech recognition, and language processing.
Pattern recognition system:
The pattern recognition system includes a sequence of steps:
Sensing ---> Preprocessing---> Segmentation---> Feature extraction---> Classification---> Post-processing
Sensing unit is a hardware, input to the unit is from the real world. It uses a transducer to acquire signals. This signal is input to the next stage called preprocessing. Preprocessing uses many filtering and non-filtering methods that helps in noise reduction and object enhancement. The preprocessed image is given as input to segmentation stage. Image segmentation is the third step, it segments single object from the set of objects like boundary, edges. The output of the image segmentation is given as input to the fourth stage called feature extraction. It uses features like boundary, line segments, and shape to describe and represent segmented objects. The Classification stage uses the feature vector as input and assigns object to a recognized class. To help a computer to find the best classifier, training algorithm and training data is used. The training algorithm uses training data to find the best classifier. There are a number of classifiers and each classifier has an error rate. The best classifier has the lowest error rate of all the other classifiers.
Deep Neural Networks:
In DNN is an algorithm to recognize patterns. It consists of several layers with nodes, where the computation usually takes place. Figure 1 shows how the network works, the input and weights are summed and is passed through activation function and finally stage is output. The activation function may be either a perceptron or sigmoid. To learn or train a network, a training data set is needed. The output from the network is approximated for all training inputs which is defined by a cost function. This cost function is also known as Mean Square Error (MSE). The training algorithm called stochastic gradient descent aims to keep the cost function as small as possible. The cost function helps to figure out the performance of the network. High cost function results in poor performance of the network so it is necessary to keep the cost function as small as possible.
The backpropagation algorithm computes the gradient of the cost function faster. The backpropagation computes the partial derivative of the cost function with respect to any weight or bias in the network. To compute the partial derivatives of cost function with respect to weights or bias it is necessary to compute the error which is related to partial derivatives. Weights will learn slowly if either the input neuron has low activation or if the output neuron is saturated due to high or low activation. The implementation of backpropagation algorithm can be improved to improve the way the network can learn. The techniques include: choice of cost function and four regularization methods (L1 and L2 regularization, dropout and artificial expansion of training data). These techniques generalize the network beyond training data, a better method to initialize weights and to choose better hyper parameters for the network. The neural networks can compute for any complicated function. Though the networks cannot be used to exactly compute any function, an approximation for the function is obtained. Increasing the number of hidden neurons improves the approximation. The hidden neurons try to output step function. By adjusting the weight and bias the step function can be obtained, usually the weight is set to large value. The position of the step is directly proportional to bias (b) and inversely proportional to weight (w).
Convolutional Neural Networks (CNN) are fast are fast to train and well adapted to classify images. It uses three ideas: local receptive fields, shared weights and pooling. CNN are adapted to translational invariance. Which means it doesn't matter where the object is, but as long as the object is in the image networks say that there is an object regardless of its position. The map from the input layer to hidden layer is called feature map. The weights and bias defining the feature map is the shared weight and bias. This shared weights and bias is called kernel or filter. CNN contain pooling layers. It also known as sub-sampling or max-pooling layer.
The time varying behavior of a neural network is known as Recurrent Neural Network (RNN). Where the activations in the hidden and output neurons is determined by the current and earlier inputs. Because of unstable gradient problem, training with RNN is very difficult. The gradient becomes smaller and smaller as it is propagated back through time which makes the learning extremely slow. If the network runs for a long time it makes the gradient extremely unstable and hard to learn. This problem is solved by using Long Short Term Memory Units (LSTM).
Programming:
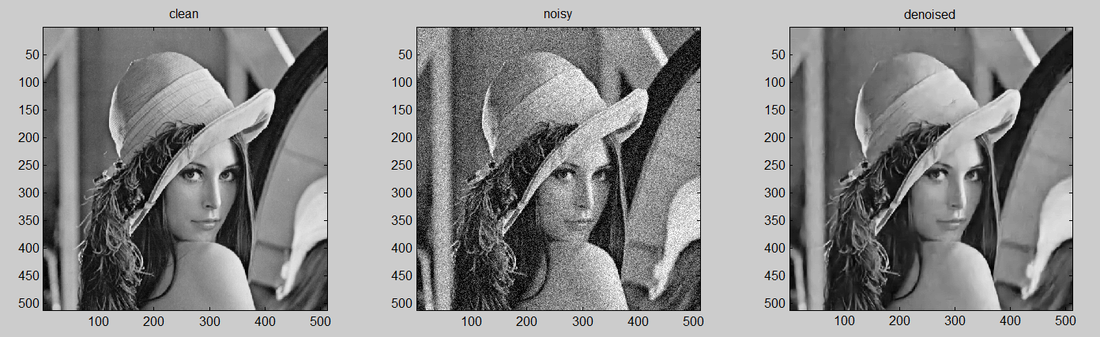
Though am not good in programming I just tried to use a simple code to denoise an image by using plain Multilayer Perceptron (MLP). The image was corrupted by Additive White Gaussian Noise (AWGN) with sigma 25. The programming language is MATLAB. The plain MLP has patch size 17 with 4 hidden layers and size 2047. I observed that by increasing the capacity, training set and patch size, MLP obtains better performance. Also, I was surprised to see that the program was very fast and completed within few seconds.
Convolutional Neural Networks (CNN) are fast are fast to train and well adapted to classify images. It uses three ideas: local receptive fields, shared weights and pooling. CNN are adapted to translational invariance. Which means it doesn't matter where the object is, but as long as the object is in the image networks say that there is an object regardless of its position. The map from the input layer to hidden layer is called feature map. The weights and bias defining the feature map is the shared weight and bias. This shared weights and bias is called kernel or filter. CNN contain pooling layers. It also known as sub-sampling or max-pooling layer.
The time varying behavior of a neural network is known as Recurrent Neural Network (RNN). Where the activations in the hidden and output neurons is determined by the current and earlier inputs. Because of unstable gradient problem, training with RNN is very difficult. The gradient becomes smaller and smaller as it is propagated back through time which makes the learning extremely slow. If the network runs for a long time it makes the gradient extremely unstable and hard to learn. This problem is solved by using Long Short Term Memory Units (LSTM).
Programming:
Though am not good in programming I just tried to use a simple code to denoise an image by using plain Multilayer Perceptron (MLP). The image was corrupted by Additive White Gaussian Noise (AWGN) with sigma 25. The programming language is MATLAB. The plain MLP has patch size 17 with 4 hidden layers and size 2047. I observed that by increasing the capacity, training set and patch size, MLP obtains better performance. Also, I was surprised to see that the program was very fast and completed within few seconds.
Conclusion:
Taking this course helps me understand the basic concepts very clearly, how the algorithm works, the parameters role in training the network, how performance can be increased by tuning the parameters and many other details about the network. This course is very interesting and was very useful for my research. I was able to understand and correlate what I learnt with the real world applications. I was amazed at this technology how it works with applications like apple’s siri and google apps.
Taking this course helps me understand the basic concepts very clearly, how the algorithm works, the parameters role in training the network, how performance can be increased by tuning the parameters and many other details about the network. This course is very interesting and was very useful for my research. I was able to understand and correlate what I learnt with the real world applications. I was amazed at this technology how it works with applications like apple’s siri and google apps.
