Dioxin's Final Report
Introduction
Pattern recognition's ultimate goal is to differ things by using the patterns. There is so many work that we can use pattern recognition, like speech recognition, fingerprint recognition, DNA sequence identification, etc.
To achieve the goal we can use tools like opencv, neural networks or deep neural networks.
Pattern recognition can divide into 5 parts:
1. sensing
2. segmentation and grouping
3. feature extraction
4. classification
5. and post processing.
In the beginning neural networking of the process we should get the input data from some transducer. Then, we separate the object from the input data so we can recognize it, and here comes the problem: how can we segment the image before we know what we want from the image? It sure is the deepest problem in pattern recognition. After we segment the image, we can extract the features from these image to do the classification. However these feature have some problems: the scale, orient, and translation are often different from cases. We have to solve these problems before we can actually "use" these features. The forth step we are going to classify these object by using the feature we get. Here we are facing a trade of : if we are often having a more accurate result, the complexes and cost are higher. Therefore we should design a system using the less (cheapest) feature and having an accurate result as well. Finally, it's time to separate it. By the information we get in the privilege step, we can output the data, or we just separate them.
OpenCV is belong to the former 3 parts, while neural network and deep neural network is belong to the last 2 parts.Pattern recognition lack either one of them would not have a satisfied result.Since we have already learned how to use OpenCV last semester, we focus on neural network and deep neural network more this semester.
Both neural network and deep neural network are kinds of machine learning. The reason why we choose these two is that pattern recognition has too much kinds of situation, like different image inputs and different targets to recognize. It is unuseful to set these parameters whenever we're in a new situation. With neural network and deep neural network we can let the neurons learned themselves and have a high accuracy at the same time.
To achieve the goal we can use tools like opencv, neural networks or deep neural networks.
Pattern recognition can divide into 5 parts:
1. sensing
2. segmentation and grouping
3. feature extraction
4. classification
5. and post processing.
In the beginning neural networking of the process we should get the input data from some transducer. Then, we separate the object from the input data so we can recognize it, and here comes the problem: how can we segment the image before we know what we want from the image? It sure is the deepest problem in pattern recognition. After we segment the image, we can extract the features from these image to do the classification. However these feature have some problems: the scale, orient, and translation are often different from cases. We have to solve these problems before we can actually "use" these features. The forth step we are going to classify these object by using the feature we get. Here we are facing a trade of : if we are often having a more accurate result, the complexes and cost are higher. Therefore we should design a system using the less (cheapest) feature and having an accurate result as well. Finally, it's time to separate it. By the information we get in the privilege step, we can output the data, or we just separate them.
OpenCV is belong to the former 3 parts, while neural network and deep neural network is belong to the last 2 parts.Pattern recognition lack either one of them would not have a satisfied result.Since we have already learned how to use OpenCV last semester, we focus on neural network and deep neural network more this semester.
Both neural network and deep neural network are kinds of machine learning. The reason why we choose these two is that pattern recognition has too much kinds of situation, like different image inputs and different targets to recognize. It is unuseful to set these parameters whenever we're in a new situation. With neural network and deep neural network we can let the neurons learned themselves and have a high accuracy at the same time.
What is NEURAL NETWORK and DEEP NEURAL NETWORK?
Neural network and deep neural network are inspired by our neural system. Our neural system coneural networkect astronomical numbers of neurons together and transfer information with axon and dendrite. Neural network and deep neural network are just like this structure: it has many neurons and have weights coneural networkect to the previous and the next layers. Most important at all, they can learned from the data they receive! By training the network, both of them can learned and tune their weights to reach the goal of recognition.
For deep neural network, it was like a complex version of neural network to solve some complex problems. Sometimes the problem is abstract that it is impossible for neural network to solve, like recognize a "kind" of things. Though it is abstract we can use something which are not that abstract to represent it. After times of iterations, we can access the abstract features with lots of non abstract features. Take cars for examples, there beetle, car, SUV, truck ... etc. It is hard for neural network to recognize that is car. However, for deep neural network, it will find out features like:
1. have 4 wheels
2. human can sit in it
3. it is wrap up by metals
4. have a steering wheel
Then deep neural network will classify things meet these features into the class "car".
For deep neural network, it was like a complex version of neural network to solve some complex problems. Sometimes the problem is abstract that it is impossible for neural network to solve, like recognize a "kind" of things. Though it is abstract we can use something which are not that abstract to represent it. After times of iterations, we can access the abstract features with lots of non abstract features. Take cars for examples, there beetle, car, SUV, truck ... etc. It is hard for neural network to recognize that is car. However, for deep neural network, it will find out features like:
1. have 4 wheels
2. human can sit in it
3. it is wrap up by metals
4. have a steering wheel
Then deep neural network will classify things meet these features into the class "car".
Reading Contents
Reading 1:What Is Pattern Recognition ?
Reading 2:Perceptron--Classical Model Of Neural Network
Reading 3:How Does Machine Learning Work ?
Reading 4:Perceptron Learning Algorithm
Reading 5:MLP and XOR
Reading 6:Back Propagation Learning Algorithm
Reading 2:Perceptron--Classical Model Of Neural Network
Reading 3:How Does Machine Learning Work ?
Reading 4:Perceptron Learning Algorithm
Reading 5:MLP and XOR
Reading 6:Back Propagation Learning Algorithm
Overfitting
Overfitting is a kind of problem that make the NEURAL NETWORK has a poor performance and make the network unstable which was cause by the reason below:
1. having too many parameters in the network
2. neurons learned noise and bad features
3. the weights are too uneven
4. training for too long
Overfitting is that the network is too close to the training data, so it will have a extremely nice performance on the training data but hard to fit the real world, the test data.
Overfitting is difficult to find out, because while training we can find out anything wired: Accuracy is high and cost is decreasing. Even look at the accuracy of test data, you can only see that it was saturated at a not that high accuracy. We can only find out overfitting problems by two ways:
1. the accuracy is saturated and is not high enough than we expect
2. the cost of test data is increasing rather then decreasing
Sometimes we can't access the test data before we've already trained the network. Then we can't use the ways above. To solve this problem, some data base like mnist would have a third kinds of data set, the validation data, to test if the network is overfitting. When the accuracy of validation is saturation then it is time to stop training.
To solve this kind of problem we can either add more training data or regularize the network.
For adding more training data set, we can make sure that the feature which neurons learned were more relative to the dataset. However the training datas are hard to access and sometimes very expensive, it may not be a good choice to solve the problem.
For regularization, it average the weights so that none of the weights will dominated the result, and that was what we don't want it to be. Besides, it just need a little bit more process, comparing with finding more training data, it sure was not a big deal.
1. having too many parameters in the network
2. neurons learned noise and bad features
3. the weights are too uneven
4. training for too long
Overfitting is that the network is too close to the training data, so it will have a extremely nice performance on the training data but hard to fit the real world, the test data.
Overfitting is difficult to find out, because while training we can find out anything wired: Accuracy is high and cost is decreasing. Even look at the accuracy of test data, you can only see that it was saturated at a not that high accuracy. We can only find out overfitting problems by two ways:
1. the accuracy is saturated and is not high enough than we expect
2. the cost of test data is increasing rather then decreasing
Sometimes we can't access the test data before we've already trained the network. Then we can't use the ways above. To solve this problem, some data base like mnist would have a third kinds of data set, the validation data, to test if the network is overfitting. When the accuracy of validation is saturation then it is time to stop training.
To solve this kind of problem we can either add more training data or regularize the network.
For adding more training data set, we can make sure that the feature which neurons learned were more relative to the dataset. However the training datas are hard to access and sometimes very expensive, it may not be a good choice to solve the problem.
For regularization, it average the weights so that none of the weights will dominated the result, and that was what we don't want it to be. Besides, it just need a little bit more process, comparing with finding more training data, it sure was not a big deal.
Regularization
Why is regularization so amazing? It just cost a little more calculate and suppress the effect of overfitting.
The main purpose of regularization is simple: suppress all the weights and make them more even. We don't want any of the weight to dominate the result, every weight are important. And we don't want the network to be too close to the training data, what we want is the network works well on real world rather only works well while training.
Here is a kind of regularization:
The main purpose of regularization is simple: suppress all the weights and make them more even. We don't want any of the weight to dominate the result, every weight are important. And we don't want the network to be too close to the training data, what we want is the network works well on real world rather only works well while training.
Here is a kind of regularization:
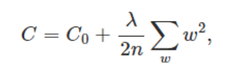
Which C0 represent to the origin cost function.
Deep Neural Network
Deep neural network is better than neural network on something which is abstract because it can combine low level features(something not that abstract or not that simple) to high level features which we can't work on before. Take the image below for example, all these categories of images are combination of the same feature sets: light, darks and edges. And these low level feature sets combine into higher level feature sets like nose, mouth, wheels, legs ... etc. We find out we can use this method on sounds! the image below shows that most of the sounds are combination of these twenty sounds features.
But here comes a problem, deep neural network are always contain more than three layers and may have a hundred thousands of neurons, if we connect all of them we will need zillions of weights, and it was ridiculous to implement. We must decrease the size for the weight sets, but how? If we see deep enough, we may find out that some neurons in the high level was just affect by only few of the neurons in the previous level. To implement this, we can use the convolution neural network. However, there are still too many weights. To decrease the size even more, it's time to decrease the size of the neurons, we combine neuron and it's neighbor into groups (pools) by choosing the maximum, the mean or the minimum from the pool which was depend by the situation. By adding these two kinds of layers we can significant decreasing the size of weight sets to make the network able to been implement.
Though we are able to implement the network, it's impossible for the network to learn with the back propagation method because when the error of the first layer go through the network, it would become too small for correction and will cause gradient diffusion. Most important of all, back propagation need the correct label the calculate the error.
While training the deep neural network, we don't train the whole network at the same time because it may take too much time. We train the deep neural network a layer at a time and optimize the whole network after all the layers are trained. Here i list some of the method: Auto Encoder, Sparse Auto Encoder, Restricted Boltzmann Machine, Deep Belief Networks, Convolutional Neural Networks.
But here comes a problem, deep neural network are always contain more than three layers and may have a hundred thousands of neurons, if we connect all of them we will need zillions of weights, and it was ridiculous to implement. We must decrease the size for the weight sets, but how? If we see deep enough, we may find out that some neurons in the high level was just affect by only few of the neurons in the previous level. To implement this, we can use the convolution neural network. However, there are still too many weights. To decrease the size even more, it's time to decrease the size of the neurons, we combine neuron and it's neighbor into groups (pools) by choosing the maximum, the mean or the minimum from the pool which was depend by the situation. By adding these two kinds of layers we can significant decreasing the size of weight sets to make the network able to been implement.
Though we are able to implement the network, it's impossible for the network to learn with the back propagation method because when the error of the first layer go through the network, it would become too small for correction and will cause gradient diffusion. Most important of all, back propagation need the correct label the calculate the error.
While training the deep neural network, we don't train the whole network at the same time because it may take too much time. We train the deep neural network a layer at a time and optimize the whole network after all the layers are trained. Here i list some of the method: Auto Encoder, Sparse Auto Encoder, Restricted Boltzmann Machine, Deep Belief Networks, Convolutional Neural Networks.
